Keep It Simple, Stupid (or the more politically correct Keep It Super Simple) is a principle that dates back millennia in one form or another – it acknowledges that systems are likely to be more reliable if they are kept simple rather than complicated. It’s also known as Ockham’s razor; translated from the Latin it is “plurality should not be posited without necessity”, which is often put forwards as “the simple explanation is most likely the correct one”, or “among competing hypotheses, the one with the fewest assumptions should be selected”.

{kind=link}
Whilst this does not always turn out to be true, especially in crime dramas, it is a useful idea to keep in mind. In Science it is often possible to be convinced that a fundamental theory is a correct one, and when you find small counter-examples it is often easier to come up with minor tweaks to the theory to explain this. If you have to keep on adding tweaks, however, it may mean that the theory is fundamentally flawed, and may have to be discarded, especially if there is a competing, simpler, theory that is better at explaining results – especially new results. This idea is well known in statistics and machine learning, but is not necessarily that common in other branches of science – the concept is called overfitting, along with the related underfitting. The concepts are well explained at https://elitedatascience.com/overfitting-in-machine-learning and https://towardsdatascience.com/overfitting-vs-underfitting-a-complete-example-d05dd7e19765.
In machine learning you are generally trying to work out what output you get when you have certain inputs. For example, you might want to grow basil indoors and wonder what the best combination of light, water, temperature and other variables (inputs) are in order to get the most basil by weight (outputs) in a given time. As a scientist what you might do is to grow 100 different plants, and for each of them vary the amount of each of these inputs over the course of a month, and then measure how much basil you get for each plant, and use that to come up with a model as to what the best combination would be. Usually you would go one step further and attempt to come up with a more general model – in this case as someone who knows about machine learning you would randomly pick around 80 of the plants (our training set) and feed the data into a piece of software that would then come up with a formula, e.g.
Weight of Basil = a.Light + b.Temperature + c.Water
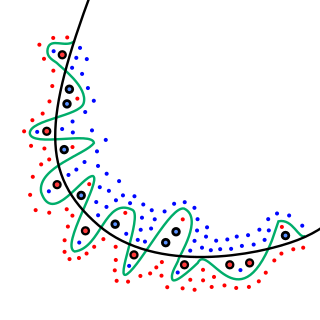
Where Light, Temperature and Water are all measured in some set units. So you basically want to work out what the values of a, b and c are in order to work out how much basil you will get. Then you might find out the best values to use are actually different to all of the values you picked initially. Now, as long as you don’t get contradictory results (i.e. when exactly the same inputs yield different output) it is possible to get a “perfect” formula in that it gives the correct answer for every plant, however this is not necessarily the best result, which is why we keep aside some of the results (e.g. 20) for testing. If the majority of these results fit the formula then it is a good one, but if not we could have overfitting. For example, as per the image below from the Elite Data Science site above, our formula may result in the green line below, which is extremely complicated compared to the much simpler black line, which although less accurate at explaining our training set is likely to be much more accurate at explaining our testing set, and in general. Also, because it is a much simpler model, it will be easier to explain to people, and also generally faster for computers to use in real life.
{kind=link}
The reason the model may still get results wrong is that there are often inputs that we don’t know about, or can’t easily measure, that can have an effect on our result. If the effect is minor then it may not matter too much in real life, but if the effect is major (or major in certain circumstances) we may have to do a considerable amount of work in improving the model. For example, in the example above we don’t mention atmospheric pressure. As the pressure does not vary too much in the one location that may not be a problem if we repeat the experiment again in the same place, but if someone else tries to duplicate our results on the top of a mountain where the pressure will be a lot less on average they may get very different results.
This is the sort of thing that Scientists spend a lot of time on; coming up with theories and then seeing if the data supports them, or coming up with experiments to gather new data. Especially in the past there were a lot of theories with very little data, but as our instruments have improved and with the advent of electricity and computers it has become possible to collect huge amounts of data and quickly test out numerous theories. Unfortunately that has also led to some Scientists forgetting about the KISS principle and coming up with theories that are so complex that they can only be tested by a computer program.
This is a problem for a number of reasons. All computer programs have a central core that is written by a person (or generally a large number of people) and so may have small errors that can lead to large mistakes, which few other people will be able to spot. Also they have assumptions built into them, and if other people cannot understand the program they may not be able to work out if the assumptions are correct or not. Complex computer-derived theories are also susceptible to overfitting, especially if the designers do not have a suitable background in information science and statistics. When you have powerful computers and huge amounts of data and hundreds of variables it is tempting to shove everything in it at once, which will often result in a theory that obscures underlying simplicity and is very hard to make use of.
How do people who are not specialists in the area know if this is occurring? As mentioned above a theory suffering from overfitting is exceptionally good at categorising existing data, but is very likely to get new data wrong. So if you read of someone saying how great a theory is and how it explains everything, but then when new observations come along they don’t fit the model or result in headlines like “Mysterious cosmic object swallowed by black hole baffles astronomers” or “An Impossible Discovery of Twisted Light could Rewrite Laws of Physics” or “The reason that comet 17P Holmes brightened so suddenly isn’t yet known” then that is a good sign that there are fundamental problems.
This is the sort of problem I started noticing in many areas of Science; firstly Chemistry back around 1985, then Astronomy a few years later, and then many other fields of Physics a few years after that. On other pages I discuss alternative models or theories that I believe are better at both explaining existing data and making predictions, but before going into them I would suggest reading my page on Per Bak, whose writings have inspired myself and many others to look for simplicity at the heart of the way the Universe works.
I have added executive summaries to the top of each of the pages on Per Bak, Miles Mathis and the Electric Universe – hopefully this will get the key points of each of those pages across and encourage people to then delve further into the details.